Comparing Reinforcement Learning with Behavioural Cloning for Guidance and Control in Space
Project overview
![Backward propagation of optimal samples (rotating frame) used to train a G&CNET with behavioural cloning [1]](/gsp/ACT/images/projects/rl_bc_gcnet/backward_propagation_of_optimal_samples.gif)
Reinforcement learning (RL) and behavioural cloning (BC) are two fundamentally different machine learning paradigms which can be used to train Guidance & Control Networks (G&CNETs) [1] to control a spacecraft.
In the UAV community RL has gained incredible success, surpassing the performance of human drone racing champions [2] and recently winning global drone racing tournaments (e.g. A2RL Grand Challenge 2025) with an approach based on G&CNETs [3].
Space, in contrast to drones, constitutes a far more deterministic environment. The absence of contact dynamics and aerodynamic effects as well as very precise system identification for actuators used in space allows us to create high fidelity models of the dynamics. Since such models cannot be obtained for drones, it begs the question whether RL is also the best suited learning paradigms for G&CNETs in space.
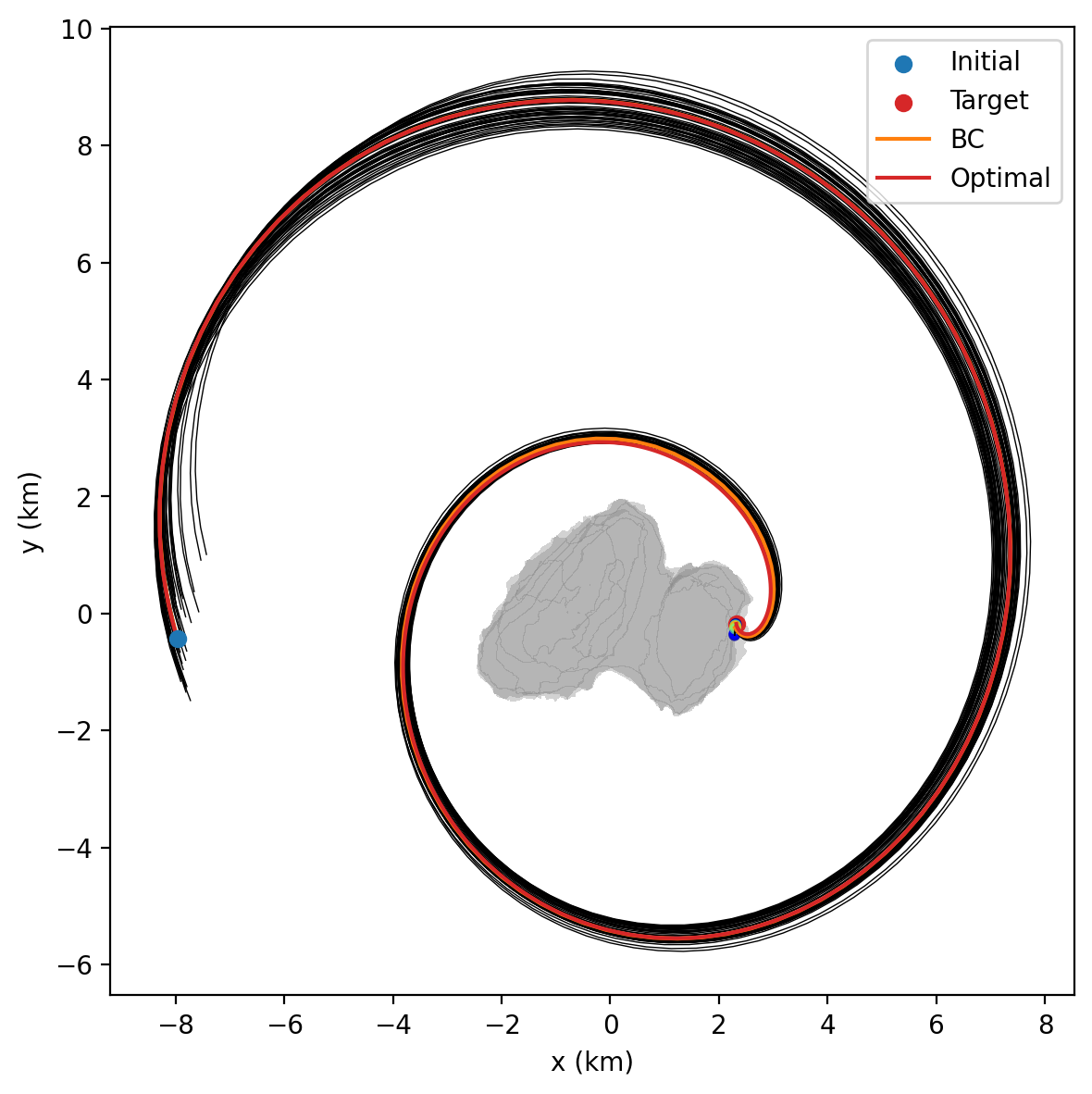
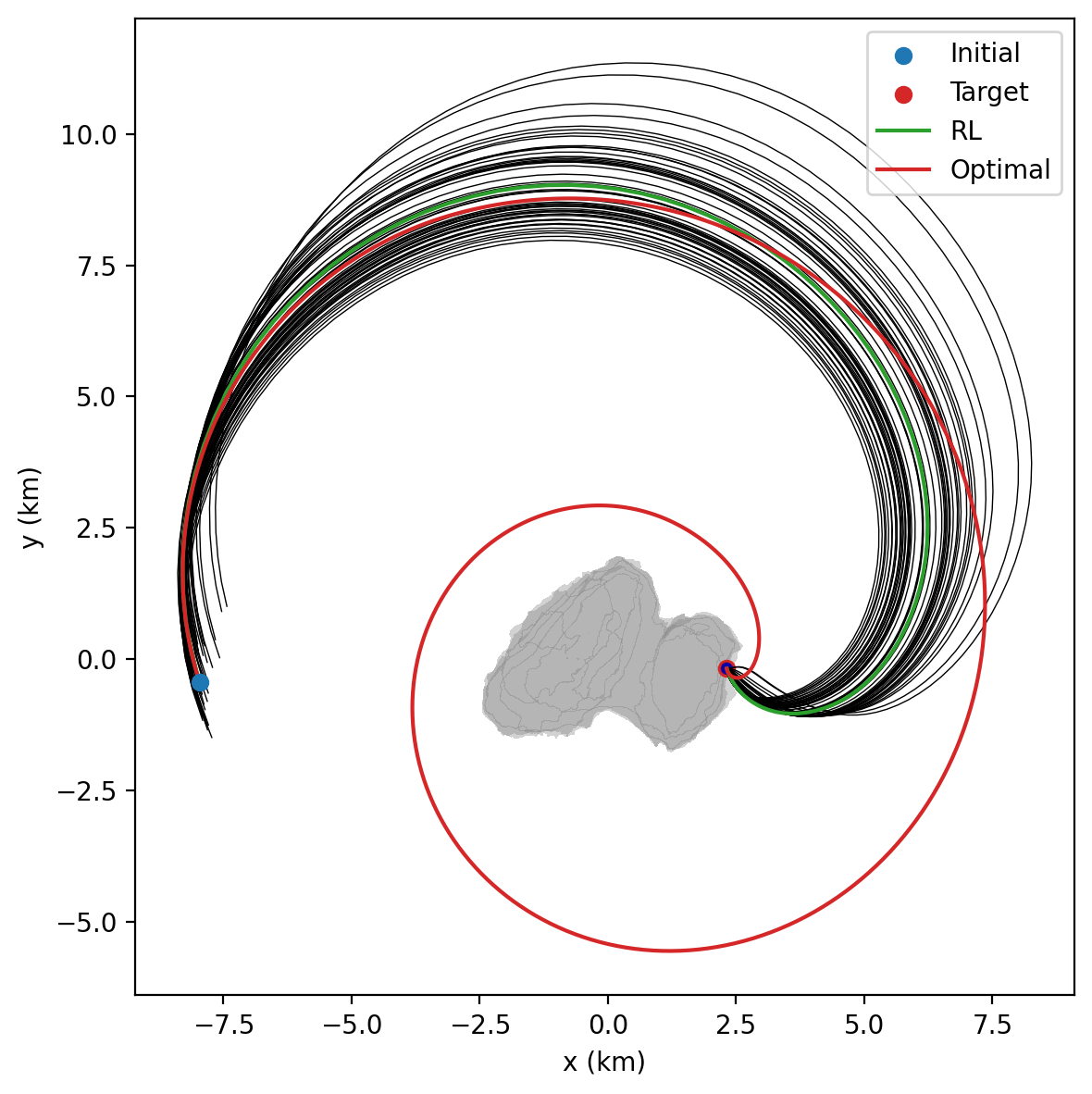
Both RL and BC have been successfully applied to train G&CNETs for space applications [1, 4]. However, the ideal learning paradigm is likely dependent on the specific task. In this project, we focus on spacecraft guidance and control tasks, such as landing on an asteroid or interplanetary transfers. Our results show that BC-trained G&CNETs excel at closely replicating expert policy behaviour,and thus the optimal control structure of a deterministic environment, but can be negatively constrained by the quality and coverage of the training dataset. In contrast RL-trained G&CNETs, beyond demonstrating a superior adaptability to stochastic conditions, can also discover solutions that improve upon suboptimal expert demonstrations,sometimes revealing globally optimal strategies that eluded the generation of training samples.
References
[1] D. Izzo, S. Origer, 2022. "Neural representation of a time optimal, constant acceleration rendezvous." Acta Astronautica, https://www.sciencedirect.com/science/article/pii/S0094576522004581.
[2] E. Kaufmann, L. Bauersfeld, A. Loquercio, M. Müller, V. Koltun, D. Scaramuzza, 2023. "Champion-level drone racing using deep reinforcement learning." https://www.nature.com/articles/s41586-023-06419-4#citeas.
[3] Ferede, R., Wagter, C. D., Izzo, D., and Croon, G. C. H. E. D., 2024, “End-to-end Reinforcement Learning for Time-Optimal Quadcopter Flight,” 2024 IEEE International Conference on Robotics and Automation, ICRA 2024, IEEE, United States, 2024, p.6172–6177. https://doi.org/10.1109/ICRA57147.2024.10611665,URLhttps://research.tudelft.nl/en/publications/end-to-end-reinforcement-learning-for-time-optimal-quadcopter-fli.
[4] A. Zavoli, L. Federici, 2020. "Reinforcement Learning for Low-Thrust Trajectory Design of Interplanetary Missions." Journal of Guidance, Control, and Dynamics, Vol. 44, No. 8, 2021, pp. 1440–1453. https://doi.org/10.2514/1.G005794, URL https://doi.org/10.2514/1.G005794.