Robust Neural Control
Background
Robust control with neural networks is most often studied within the reinforcement learning (RL) paradigm, where deep policies have achieved impressive results in games such as Go, chess, and StarCraft, as well as in robotics and continuous control. Despite these successes, RL typically depends on carefully engineered reward functions, extensive interaction with the environment, and substantial hyperparameter tuning, which can hinder scalability and real-world deployment.
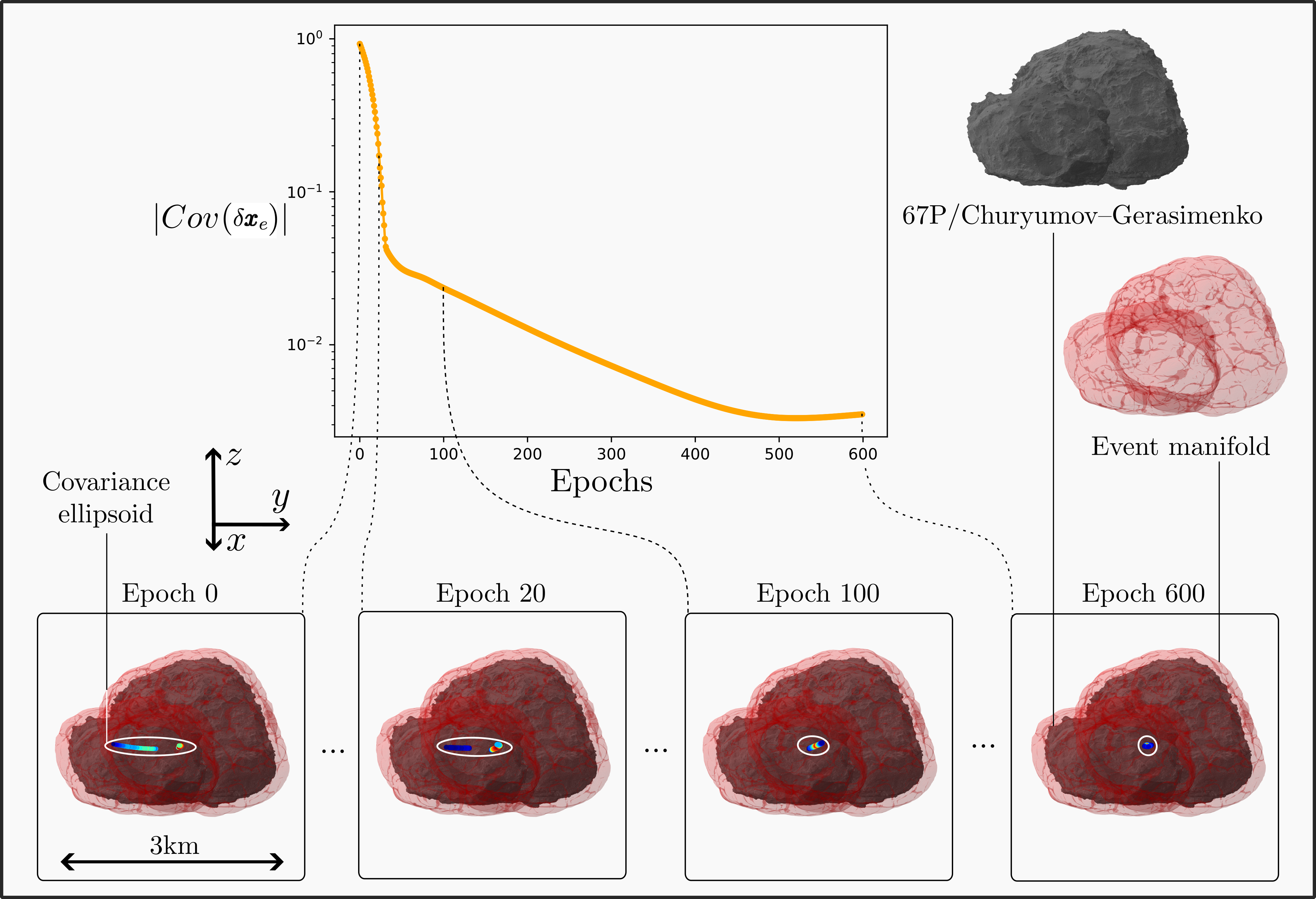
In this project, we explore an alternative direction that builds on our recent work on NeuralODEs [1], [2]. Rather than learning policies through trial-and-error, we start from deterministic neural controllers and directly optimize their robustness to uncertainty. By embedding uncertainty-aware objectives into differentiable dynamical models, we aim to bypass training the uncertain control problem from scratch while retaining the expressive power of neural policies.
Project Goals
We are developing Robust NeuralODEs, a framework for enhancing pre-trained neural controllers so they remain reliable in the presence of uncertain initial conditions, model parameters, and disturbances. Instead of learning a new policy from scratch, we propagate uncertainty through differentiable system dynamics and directly minimize measures of terminal state dispersion.
Our approach corrects specifically a pre-trained deterministic system to reduce sensitivity to uncertainty. This shifts the focus from policy learning to policy strengthening, enabling neural controllers that are more stable, predictable, and suitable for deployment in safety-critical, real-world systems.
References
[1] Acciarini, G. Space Trajectory Design in Uncertain Environments. PhD Dissertation, University of Surrey, 2025.
[2] Izzo, D., Origer, S., Acciarini, G., & Biscani, F. “High-order expansion of neural ordinary differential equation flows.” Science Advances, 11(51), 2025.